450 num:50005000
10
C++ 的 ScopeExitGuard
C++ 提供了 RAII 机制,并提倡使用它来管理各种资源,可是在实际中会发现这一套使用起来并不如想象中的那么方便。在 Linux 下开发会遇到大量 open() / close() 或是 malloc() / free() 类似操作,而且大部分都没有现成好用的 C++ wrapper,如果每组操作都自己去寨一个 class OperationGuard 只用来管理资源释放未免又显得过于繁琐。
其实我需要的只是在退出作用域时自动执行一些清理操作,如果能方便的把要进行的操作封装在一个临时对象的析构函数里就好了。在网上搜索了一下,果然已经有 很多人想到了这个问题,现成的实现有 Boost 的 SCOPE_EXIT,看了一下支持的功能很多,用起来也比想象中复杂了不少。于是还是自己来寨一个好了,也不用很复杂:(以下实现参考了SCOPE(EXIT) IN C++11)
template<class F>
class ScopeExitGuard_Impl{
F _f;
public:
ScopeExitGuard_Impl(F f) : _f(f) {}
~ScopeExitGuard_Impl(){
_f();
}
};
template<class F>
ScopeExitGuard_Impl<F> ScopeExitGuard(F f){
return ScopeExitGuard_Impl<F>(f);
}
#define SCOPE_EXIT_GUARD(code) \
auto scope_exit_##__LINE__ = ScopeExitGuard([&]{code;})
C++11 的 lambda 真是好用啊。在 SCOPE(EXIT) IN C++11 那篇中,lambda 使用了 [=] 来获取外部变量,这样一来就只能读取,无法改写。我在上面的 lambda 中改为 [&] 方便改写外部变量。
使用起来很简单:
int a = 1;
{
SCOPE_EXIT_GUARD(a = 2);
a = 3;
}
cout << a << endl; // print: 2
{
int *p = (int*)::operator new(100 * sizeof(int));
// label 1
SCOPE_EXIT_GUARD(::operator delete(p));
for (int i = 0; i < 10; ++i){
p[i] = i;
}
}
如果在 ::operator new() 语句或 label 1 处抛出异常,::operator delete() 就不会被调用,因此只需把释放资源的 SCOPE_EXIT_GURAD 语句与申请资源的语句放在一起就好。
指针和虚函数表
前两天在水木 C++ 版看到两个题目,分别是关于指针和 class 的虚函数表的。关于指针和数组,之前已经打过很久的交道了,比较简单。不过虚函数表以及 class 成员的内存布局一直是模模糊糊的概念,趁此机会把《C++对象模型》拿出来研究了一把。
题目一
#include<stdio.h>
int main()
{
int a[5] = {1, 2, 3, 4, 5};
int *ptr = (int*)(&a + 1);
printf("%d,%d\n", *(a+1), *(ptr-1));
}
输出什么?
数组和指针类型的互相转换,只要弄清楚指针所指地址以及所指的类型就容易分析了:
-
a的类型是int[5],表示一个长度为 5 的int型数组 -
由于
a的类型是数组,因此对a进行算数运算时,其所指地址是以sizeof(A[0])为单位变化的,这里即是sizeof(int),因此*(a+1)是a[1] -
对
a取地址,得到的类型是int (*)[5],这是一个指针,其指向一个含有 5 个int的数组。因此&a+1会使地址向后移动 5 个int的空间,得到a[5]的地址。 -
ptr是int*类型,因此它的算数运算的单位是sizeof(int),ptr-1即可得到a[4]的地址。 - 综上,程序输出 2,5
题目二
#include <iostream>
using namespace std;
class A {
virtual void g() {
cout << "A::g" << endl;
}
private:
virtual void f() {
cout << "A::f" << endl;
}
};
class B : public A {
void g() {
cout << "B::g" << endl;
}
virtual void h() {
cout << "B::h" << endl;
}
};
typedef void(*Fun)(void);
int main() {
B b;
Fun pFun;
for (int i = 0; i < 3; i++) {
pFun = (Fun)*((int*)* (int*)(&b) + i);
pFun();
}
}
输出什么?
看那一串丧心病狂的指针操作!!
class 层次很简单,A 里有两个虚函数 g() 和 f(),B 里重写了 g(),又添了一个 h()。A 里那个 private 是多余,所有函数都是 private 的。 main() 里主要就是对那个函数指针 pFun 赋值,然后调用。看来所有的内容都在那个指针操作里。
-
(&b)得到b的地址,类型是B* -
*(int*)(&b)将b的地址按int型指针来解释,并取出这个int值。相当于将b的前 4 个字节 (32位环境下) 当成一个int型读出。假设读出的值是vptr(好吧……其实就是 vptr) -
*((int*)vptr + i)将上一个操作取出的值再当成一个地址,并添加i个单位偏移。由于是int*类型,因此每次偏移一个sizeof(int)的空间,即 4 字节。粗略来说就相当于读出vptr[i]的值。 -
最后再转换为
Fun的函数指针。
用一个图来看一下:
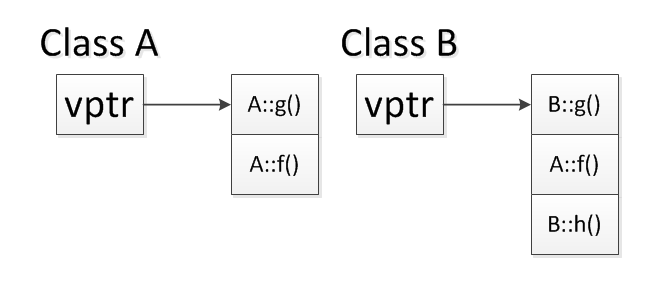
class A 里有两个虚函数,因此它的虚函数表只有两项,分别是 A::g() 和 A::f()。class B 继承自 A,因此它必须首先照搬 A 的虚函数表(前 2 项),然后再添加自己新加的 B::h(),同时在 B 中又重写了 g(),因此 B 的虚函数表里把 A::g() 的位置替换为 B::g()。
根据前面指针的分析可以看出,三次循环分别调用了 B::g(), A::f() 和 B::h()。不过这个调用比较粗暴,完全无视了函数参数。本身类成员函数是带有一个 this 指针做参数的,不过既然这里也没有使用成员变量,因此也就没什么影响了。
以上程序能够成功运行的条件是 class 的虚函数指针位于对象的头部。我试着在 class A 和 class B 中分别添加一个 int 成员,输出结果依然不变(VS2013 和 gcc4.9.2 下),说明这两个编译器都将虚函数指针放在对象头部,没有再试验其他环境,不知道会不会有不同结果。另外,如果是 64位 环境,应将指针变换那一行的所有 int 换成 int64_t 或 long long,不然指针和 int 所占空间不同,地址运算会出错。
File I/O 效率 C vs C++ (一)
继续关注文件读写...这次测试写的效率
其实关于这个问题的讨论似乎总会以类似语言信仰问题而告终,再加 C++ IO 库的复杂性,很多半调子 C++ 程序员总会出现各种误用,反过来却作为攻击 C++ IO 效率低的凭证。
比如经常有人边在输出时大量使用类似
fout<<...<<endl;
的语句边嚷嚷着写文件速度超慢的,只能说这些人根本不知道自己写的句子都做了什么...
所以说在评价任何东西之前先要做到最起码的了解
咱也算是大致研究过 C++ IO stream 各方面的内容,虽然不能说完全掌握仍在学习中,但自认为还是可以写点东西的。
咱也算是大致研究过 C++ IO stream 各方面的内容,虽然不能说完全掌握仍在学习中,但自认为还是可以写点东西的。
总之还是用数据说话。
平台 XPsp3 + VC2008 Express Edition SP1 + STLport / MinGW(GCC4.4.0)
实验内容:
共做了三种类型写入的比较,每种类型采用几种不同方法实现:
1. 纯字节流写入
(1) C fputs()
(2) C fprintf()
(3) C++ ofstream<<
(4) C++ ofstream.rdbuf()->sputn()
2. 宽字符流通过转码写入
(1) C++ locale + wofstream<<
(2) C++ codecvt<> facet + ofstream.rdbuf()->sputn()
(3) WinAPI WideCharToMultiByte() + ofstream<<
3. 格式化写入 (一个 int 一个 double + 一个字符串)
(1) C fprintf()
(2) C++ ofstream<<
(3) C++ ostream.rdbuf()->sputn() sputc() + num_put<> facet
共做了三种类型写入的比较,每种类型采用几种不同方法实现:
1. 纯字节流写入
(1) C fputs()
(2) C fprintf()
(3) C++ ofstream<<
(4) C++ ofstream.rdbuf()->sputn()
2. 宽字符流通过转码写入
(1) C++ locale + wofstream<<
(2) C++ codecvt<> facet + ofstream.rdbuf()->sputn()
(3) WinAPI WideCharToMultiByte() + ofstream<<
3. 格式化写入 (一个 int 一个 double + 一个字符串)
(1) C fprintf()
(2) C++ ofstream<<
(3) C++ ostream.rdbuf()->sputn() sputc() + num_put<> facet
前两类比较时写入的内容是完全一致的,也可以横向做下参照。
结果:(由于和硬盘寻道时间等也有关系,尽量多次测试取受影响最小的值)
以 C Runtime library 的 fputs 函数所用时间为 1.0 做基准
VC2008EE + VC STL:
text out C fputs() 1.0
text out C fprintf() 2.0
text out C++ ofstream << 1.2
text out C++ ofstream rdbuf()->sputn() 0.8
wText out C++ wofstream deflocale 25.0
wText out C++ locale codecvt 7.5
wText out C++ ofstream + WinAPI 1.5
wText out C++ locale codecvt 7.5
wText out C++ ofstream + WinAPI 1.5
Format data out C fprintf() 2.0
Format data out C++ ofstream << 4.0
Format data out C++ ofs num_put facet 3.0
Format data out C++ ofstream << 4.0
Format data out C++ ofs num_put facet 3.0
首先用 VC 自带的标准库,可以看到直接用 C++ fstream 的 << 效率与 C 库函数相比还是略低一些,但差距并没有到不可忍受的地步,考虑到 C++ IO stream 的各种特性,这些还是可以接受的。
而直接调用下层 rdbuf()->sputn() 函数却比 fputs() 效率更高,让我对 C++ IO 库的进一步优化仍有希望。
在 Unicode 大行其道的今天,宽字符的读写已成为必需,但使用 locale 配合 wstream 来做的话效率确实无法接受,从上面看居然比调用 WinAPI 的方法慢几十倍。我还是严重怀疑 VC STL 的实现有问题,只是换做直接调用 codecvt<> facet 就能提高好几倍效率。
格式化读写一向是 C++ IO stream 被重点诟病的地方,与 fprintf() 函数整相差一倍,即使直接调用 num_put (去掉了构造 ios_base::sentry 对象产生的流同步、空白跳过等操作),仍然有 50% 的差距。
其实从理论上来说,C++ 的格式化读写应当是比 C 的 fprintf() 函数要快的,因为 fprintf() 总要有一个解析格式字符串的过程,这个只能放在运行时,而 C++ 的格式是通过多个连续函数调用控制的,可以在编译时即进行优化。但实践往往存在各种变数 = =
而直接调用下层 rdbuf()->sputn() 函数却比 fputs() 效率更高,让我对 C++ IO 库的进一步优化仍有希望。
在 Unicode 大行其道的今天,宽字符的读写已成为必需,但使用 locale 配合 wstream 来做的话效率确实无法接受,从上面看居然比调用 WinAPI 的方法慢几十倍。我还是严重怀疑 VC STL 的实现有问题,只是换做直接调用 codecvt<> facet 就能提高好几倍效率。
格式化读写一向是 C++ IO stream 被重点诟病的地方,与 fprintf() 函数整相差一倍,即使直接调用 num_put (去掉了构造 ios_base::sentry 对象产生的流同步、空白跳过等操作),仍然有 50% 的差距。
其实从理论上来说,C++ 的格式化读写应当是比 C 的 fprintf() 函数要快的,因为 fprintf() 总要有一个解析格式字符串的过程,这个只能放在运行时,而 C++ 的格式是通过多个连续函数调用控制的,可以在编译时即进行优化。但实践往往存在各种变数 = =
VC2008EE + STLport5.2.1:
text out C fputs() 1.0
text out C fprintf() 2.0
text out C++ ofstream << 0.7
text out C++ ofstream rdbuf()->sputn() 0.6
text out C fputs() 1.0
text out C fprintf() 2.0
text out C++ ofstream << 0.7
text out C++ ofstream rdbuf()->sputn() 0.6
wText out C++ wofstream deflocale 7.5
wText out C++ locale codecvt 7.0
wText out C++ ofstream + WinAPI 1.0
wText out C++ locale codecvt 7.0
wText out C++ ofstream + WinAPI 1.0
Format data out C fprintf() 2.0
Format data out C++ ofstream << 2.0
Format data out C++ ofs num_put facet 1.7
Format data out C++ ofstream << 2.0
Format data out C++ ofs num_put facet 1.7
STLport 的 C 库函数完全是照搬 VC 的标准运行库,而只是重新实现了整个 C++ 库,所以 C 函数的效率与上一例是相同的,可直接横向比较。
面对这样的结果,我只能说 STLport 太赞了!!再考虑到其他的种种特性,赶紧扔掉 VC STL 全部换用 STLport 吧
不过转码看来确实是一个平台相关的特性,仍然无法比过 WinAPI 的效率
面对这样的结果,我只能说 STLport 太赞了!!再考虑到其他的种种特性,赶紧扔掉 VC STL 全部换用 STLport 吧
不过转码看来确实是一个平台相关的特性,仍然无法比过 WinAPI 的效率
MinGW GCC4.4.0 + libstdc++:
text out C fputs() 1.5
text out C fprintf() 2.7
text out C++ ofstream << 6.0
text out C++ ofstream rdbuf()->sputn() 2.7
mingw libstdc++ doesnot surpport other locale...
mingw libstdc++ doesnot surpport other locale...
wText out C++ ofstream + WinAPI 2.1
mingw libstdc++ doesnot surpport other locale...
wText out C++ ofstream + WinAPI 2.1
Format data out C fprintf() 3.0
Format data out C++ ofstream << 6.6
Format data out C++ ofs num_put facet 5.8
Format data out C++ ofstream << 6.6
Format data out C++ ofs num_put facet 5.8
MinGW 貌似比较慢,是因为 MinGW 默认输出按 UTF-8 编码,对中文来说,字节数是 ANSI 的 1.5 倍。只有调用 API 的那个例子保持了 ANSI 编码。
除以 1.5 的话可以看到 C 库函数的效率与 VC 差不多,但 C++ 的效率比 VC 略低,与 STLport 比就差更远了。毕竟 GCC + libstdc++ 在 Win 平台不是原生支持,只作为跨平台的特性这样也足够了。
没有用 MinGW + STLport 做实验,不知能不能达到 VC 的效率。
除以 1.5 的话可以看到 C 库函数的效率与 VC 差不多,但 C++ 的效率比 VC 略低,与 STLport 比就差更远了。毕竟 GCC + libstdc++ 在 Win 平台不是原生支持,只作为跨平台的特性这样也足够了。
没有用 MinGW + STLport 做实验,不知能不能达到 VC 的效率。
-------------------------------------------------------------
以前使用 C++ 的 IO stream 做输入输出时总担心效率问题,现在有了 STLport 做支持就可以放心大胆的用了。
以前使用 C++ 的 IO stream 做输入输出时总担心效率问题,现在有了 STLport 做支持就可以放心大胆的用了。
但可以看到 C++ 的流式 IO 非常依赖于库实现,在各平台上的表现大概不如 C 库函数来得稳定。
而且使用除 "C" 之外的 locale 时效率确实还是有问题,转码的话还是直接调用平台 API 省时省力又高效。MinGW 考虑不引入 locale 部分也是有道理的啊...
而且使用除 "C" 之外的 locale 时效率确实还是有问题,转码的话还是直接调用平台 API 省时省力又高效。MinGW 考虑不引入 locale 部分也是有道理的啊...
这次全是 O,下次再比较 I 的情况...
最后按惯例是程序代码:
-
// test the performance of C I/O & C++ streams & C++ codecvt facet
-
#include<cstdio>
-
#include<iostream>
-
#include<fstream>
-
#include<locale>
-
#include<cstdlib>
-
#include<ctime>
-
#include<windows.h>
-
using namespace std;
-
-
const int testsize = 50000;
-
-
int main(){
-
char cstr[] = "这是实验字符串这是实验字符串这是实验字符串这是实验字符串这是实验字符串这是实验字符串这是实验字符串这是实验字符串";
-
wchar_t wstr[] = L"这是实验字符串这是实验字符串这是实验字符串这是实验字符串这是实验字符串这是实验字符串这是实验字符串这是实验字符串";
-
char buffer[200];
-
int cstrlen = strlen(cstr);
-
locale defloc("");
-
-
clock_t start;
-
FILE *cfile;
-
ofstream fout;
-
wofstream wfout;
-
-
// pure text ...........................
-
start = clock();
-
cfile = fopen("text_out_C_fputs.txt", "w");
-
for(int i = 0; i < testsize; ++i){
-
fputs(cstr, cfile);
-
fputc('\n', cfile);
-
}
-
fclose(cfile);
-
printf("Text out C fputs: %d\n", clock()-start);
-
-
start = clock();
-
cfile = fopen("test_out_C_fprintf.txt", "w");
-
for(int i = 0; i < testsize; ++i){
-
fprintf(cfile, "%s\n", cstr);
-
}
-
fclose(cfile);
-
printf("Text out C fprintf: %d\n", clock()-start);
-
-
fout.clear();
-
start = clock();
-
fout.open("text_out_Cpp_ofstream.txt");
-
for(int i = 0; i < testsize; ++i){
-
fout << cstr << '\n';
-
}
-
fout.close();
-
printf("Text out Cpp ofstream: %d\n", clock()-start);
-
-
fout.clear();
-
start = clock();
-
fout.open("text_out_Cpp_rdbuf.txt");
-
for(int i = 0; i < testsize; ++i){
-
fout.rdbuf()->sputn(cstr, cstrlen);
-
fout.rdbuf()->sputc('\n');
-
}
-
fout.close();
-
printf("Text out Cpp rdbuf: %d\n", clock()-start);
-
-
// wchar_t text ...............................
-
wfout.clear();
-
start = clock();
-
wfout.open("wtext_out_Cpp_wofs_defloc.txt");
-
wfout.imbue(defloc);
-
for(int i = 0; i < testsize; ++i){
-
wfout << wstr << L'\n';
-
}
-
wfout.close();
-
printf("wText out Cpp wofs with default locale: %d\n", clock()-start);
-
-
fout.clear();
-
start = clock();
-
char *next;
-
const wchar_t *wnext;
-
mbstate_t st;
-
fout.open("wtext_out_Cpp_codecvt_facet.txt");
-
for(int i = 0; i < testsize; ++i){
-
use_facet<codecvt<wchar_t, char, mbstate_t> >(defloc).out(
-
st, wstr, wstr+sizeof(wstr)/2-1, wnext,
-
buffer, buffer+sizeof(buffer)-1, next);
-
fout.rdbuf()->sputn(buffer, next-buffer);
-
fout.rdbuf()->sputc('\n');
-
}
-
fout.close();
-
printf("wText out Cpp ofs with codecvt facet: %d\n", clock()-start);
-
-
fout.clear();
-
start = clock();
-
fout.open("wtext_out_Cpp_ofs_WinAPI.txt");
-
for(int i = 0; i < testsize; ++i){
-
WideCharToMultiByte(CP_ACP, 0, wstr, -1, buffer, 200, NULL, NULL);
-
fout << buffer << '\n';
-
}
-
fout.close();
-
printf("wText out Cpp ofs with WideCharToMultiByte API: %d\n",
-
clock()-start);
-
-
// Format out ...........................................
-
srand((unsigned)time(NULL));
-
-
char datastr[] = "TestDataString实验格式化字符串";
-
start = clock();
-
cfile = fopen("format_data_out_C_fprintf.txt", "w");
-
for(int i = 0; i < testsize; ++i){
-
fprintf(cfile, "%d %lf %s\n",
-
rand(), double(rand())/RAND_MAX, datastr);
-
}
-
fclose(cfile);
-
printf("Format data out C fprintf: %d\n", clock()-start);
-
-
fout.clear();
-
start = clock();
-
fout.open("format_data_out_Cpp_ofstream.txt");
-
for(int i = 0; i < testsize; ++i){
-
fout << rand() << ' ' << double(rand())/RAND_MAX << ' '
-
<< datastr << '\n';
-
}
-
fout.close();
-
printf("Format data out Cpp ofstream: %d\n", clock()-start);
-
-
fout.clear();
-
start = clock();
-
fout.open("format_data_out_Cpp_ofs_facet.txt");
-
for(int i = 0; i < testsize; ++i){
-
use_facet<num_put<char> >(locale::classic()).put(
-
ostreambuf_iterator<char>(fout), fout, ' ', (long)rand());
-
fout.rdbuf()->sputc(' ');
-
use_facet<num_put<char> >(locale::classic()).put(
-
ostreambuf_iterator<char>(fout), fout, ' ',
-
double(rand())/RAND_MAX);
-
fout.rdbuf()->sputc(' ');
-
fout.rdbuf()->sputn(datastr, sizeof(datastr) - 1);
-
fout.rdbuf()->sputc('\n');
-
}
-
fout.close();
-
printf("Format data out Cpp ofs with facet: %d\n", clock()-start);
-
-
system("pause");
-
}
fstream 文件 IO 点滴
很多时候较大数据量的文件 IO 总是成为瓶颈,为了提高效率,有时想要先将文件大块大块的读入再行处理。下面分析两种惯常的处理手法。
1. 将文件一次性读入 string 中。
貌似 std::getline 、 istream::getline 或是 operator<< operator>> 等都不提供一次读到文件结尾的机制,只有 istreambuf_iterator 可以做到:
ifstream in("input.txt");
string instr((istreambuf_iterator<char>(in)), istreambuf_iterator<char>());
string instr((istreambuf_iterator<char>(in)), istreambuf_iterator<char>());
string 的构造函数前一个参数要多加一层 () 以免编译器误认为是函数声明 = = ...
这样读入 string 会随着内容动态增长,空间不足时会触发额外的 realloc 及 copy 操作,为提高效率有必要预分配足够的空间:
ifstream in("input.txt");
in.seekg(0, ios::end);
streampos len = in.tellg();
in.seekg(0, ios::beg);
string instr;
instr.reserve(len);
instr.assign(istreambuf_iterator<char>(in), istreambuf_iterator<char>());
in.seekg(0, ios::end);
streampos len = in.tellg();
in.seekg(0, ios::beg);
string instr;
instr.reserve(len);
instr.assign(istreambuf_iterator<char>(in), istreambuf_iterator<char>());
2. 将文件一次性读入 stringstream 中。
filebuf 和 stringbuf 无法直接通过 rdbuf() 重定向,因此从 filebuf 到 stringbuf 需要一次 copy 操作。最简单的方法是直接复制整个 streambuf :
ifstream in("input.txt");
stringstream ss;
ss<<in.rdbuf();
stringstream ss;
ss<<in.rdbuf();
与 string 的情况相同,这里同样也有一个空间 realloc 及 copy 的问题。但 streambuf 的缓冲区不是那么方便操作的,解决方法是我们给他手动指定一个空间:
ifstream in("input.txt");
in.seekg(0, ios::end);
streampos len = in.tellg();
in.seekg(0, ios::beg);
vector<char> buffer(len);
in.read(&buffer[0], len);
stringstream ss;
ss.rdbuf()->pubsetbuf(&buffer[0], len);
in.seekg(0, ios::end);
streampos len = in.tellg();
in.seekg(0, ios::beg);
vector<char> buffer(len);
in.read(&buffer[0], len);
stringstream ss;
ss.rdbuf()->pubsetbuf(&buffer[0], len);
最后再顺便 BS 一下 VC 的 STL = =...
虽然 VC 的编译器效率没的说,但被 STL 拖后腿的话不就白搭了嘛。在文件 IO 方面 (fstream) 比起 MinGW (GCC 4.4.0) 带的要慢好几倍。GCC 的 fstream 格式化读写效率与 C 的比已经不分伯仲,以后应该还会有进一步的提升空间 (编译时格式控制 vs 执行时)
另外上面最后一段程序在 VS2008 (VC9.0) 下应该无法得到预想的结果,跟踪进去看了一下,VC 标准库里的 pubsetbuf 函数体居然是空的!内容如下(中间还有一层函数调用):
virtual _Myt *__CLR_OR_THIS_CALL setbuf(_Elem *, streamsize)
{ // offer buffer to external agent (do nothing)
return (this);
}
{ // offer buffer to external agent (do nothing)
return (this);
}
看来是等着我们来继承了啊 = = 。而在 MinGW (GCC 4.4.0) 中可以得到预期的结果。
从 std::list 中 size() 的时间复杂度引出的讨论...
很奇怪的,或者说是一个不应成为问题的问题...
std::list 的 size() 方法时间复杂度是多少?第一感觉应该是 O(1) 没错吧,多一个变量用于储存链表长度应该是很轻易的事情。于是有了下面这段代码:
#include<iostream>
#include<list>
#include<ctime>
using namespace std;
int main(){
time_t start, finish;
int num = 0;
list<int> coll;
start = clock();
for(int i=0;i<10000;++i){
coll.push_back(i);
num += coll.size();
}
finish = clock();
cout<<finish - start<<" num:"<<num<<endl;
coll.clear();
start = clock();
for(int i=0;i<10000;++i){
coll.push_back(i);
}
finish = clock();
cout<<finish - start<<endl;
return 0;
}
#include<list>
#include<ctime>
using namespace std;
int main(){
time_t start, finish;
int num = 0;
list<int> coll;
start = clock();
for(int i=0;i<10000;++i){
coll.push_back(i);
num += coll.size();
}
finish = clock();
cout<<finish - start<<" num:"<<num<<endl;
coll.clear();
start = clock();
for(int i=0;i<10000;++i){
coll.push_back(i);
}
finish = clock();
cout<<finish - start<<endl;
return 0;
}
对两个循环分别计时比较。前一个循环只比后一个多了一句 num += coll.size(); 为了使编译器确实生成 list::size() 的代码。
在 MinGW 5.1.4 中 (GCC 3.4.5) 编译结果运行如下:
可以看到,前一个循环居然比后一个多花了几乎 45 倍的时间...当我把循环次数从 10000 加到 100000 时程序半天没出结果...
由此有理由猜测 std::list 的 size() 方法难道是 O(N) 的?果然,在头文件中发现了这一段:
size_type
size() const
{ return std::distance(begin(), end()); }
size() const
{ return std::distance(begin(), end()); }
直接调用 <algorithm> 算法库函数 distance() 计算元素个数……怪不得这么慢。然后又用 VS2008 (VC9.0)编译,结果如下:
30 num:50005000
60
60
奇怪的是前一个循环居然比后一个还快...不过至少知道 VS2008 (VC9.0)里的 size() 应该是 O(1) 的。同样查看了一下代码,如下:
size_type size() const
{ // return length of sequence
return (_Mysize);
}
{ // return length of sequence
return (_Mysize);
}
_Mysize 是一个 size_type 类型的变量。疑问解决。不过又有了新问题:
--------------- 咱 -- 是 -- 分 -- 隔 -- 线 ------------------
为什么 GCC 里要把 list::size() 的复杂度搞成 O(N)?
一通搜索后终于看到有这样的讨论:关于 list::splice() 函数。
list 是链表结构,它的优势就在于可以 O(1) 的时间复杂度任意插入删除甚至拼接 list 片段(删除时可能不是,因为要释放内存),list::splice() 是一个很强大的功能,它可在任意位置拼接两个 list,这正是 list 的优势。如果我们在类内部以一个变量储存 list 的长度,那么 splice() 之后新 list 的长度该如何确定?这是一个很严峻的问题,如果要在拼接操作时计算拼接部分的长度,那么将把 O(1) 的时间变成 O(N),这么一来 list 相对 vector 的优势就消失殆尽。
面对这个问题,GCC 和 VC 的 STL 库作者们做了不同的选择。GCC 选择舍弃在 list 内部保存元素数量,而在 size() 时直接从头数到尾,这便出现了开头看到的 O(N) 时间才算出 size();相反,VC 中有了变量 _Mysize ,无论在 insert() erase() splice() 或是 push() pop() 时都需要对其做相应修改。在上面的两个试验中已经看出同样是 10000 个 push_back() 操作,VC 花的时间比较长,不过也仅仅是一个 inc 指令,差别很小就是了。上面几种会改变 list 内容的操作中,大部分对元素数量的影响只是 +1 或 -1,只有 splice() 需要计算拼接部分元素个数,这个差别就大了,咱还是继续用实验证明吧:
#include<iostream>
#include<list>
#include<ctime>
using namespace std;
int main(){
time_t start,finish;
list<int> col;
col.push_back(1);
col.push_back(10000);
list<int> col2;
start = clock();
for(int i=2;i<10000;++i)
col2.push_back(i);
finish = clock();
cout<<finish - start<<endl;
int num = 0;
start = clock();
for(int i=0;i<10000;++i){
col.splice(++col.begin(),col2,++col2.begin(),--col2.end());
num += *(++col.begin());
col2.splice(++col2.begin(),col,++col.begin(),--col.end());
num += *(++col2.begin());
}
finish = clock();
cout<<finish - start<<" num:"<<num<<endl;
return 0;
}
#include<list>
#include<ctime>
using namespace std;
int main(){
time_t start,finish;
list<int> col;
col.push_back(1);
col.push_back(10000);
list<int> col2;
start = clock();
for(int i=2;i<10000;++i)
col2.push_back(i);
finish = clock();
cout<<finish - start<<endl;
int num = 0;
start = clock();
for(int i=0;i<10000;++i){
col.splice(++col.begin(),col2,++col2.begin(),--col2.end());
num += *(++col.begin());
col2.splice(++col2.begin(),col,++col.begin(),--col.end());
num += *(++col2.begin());
}
finish = clock();
cout<<finish - start<<" num:"<<num<<endl;
return 0;
}
首先是 MinGW (GCC 3.4.5) 的结果:
10
0 num:60000
0 num:60000
可以看到 10000 次 push 是 10,相对的 20000 次 splice() 几乎没花时间 = =
然后是 VS2008 (VC9.0):
20
2714 num:60000
2714 num:60000
差别非常明显,花了2秒多才完成。当我把循环次数改成 100000 后 GCC 仍是眨眼间的事,VC 却长时间运行无结果……
怎么说呢,GCC 显然是追求效率至上,尽量体现出 list 的优势所在,不过我觉得这么一来倒不如干脆不提供 list 的 size() 方法,有需求的程序员可以自己维护一个变量记录长度,以免误认为 size() 是 O(1) 的而犯下严重错误。相对的 VC 强调功能性和整体效率,可能在实际中需要对链表一段内容做 splice() 操作的机会远远小于求 size() 的操作,所以舍弃前者而保留后者,不过要维护 _Mysize 其他相关函数中也增加了开销。一个见仁见智的问题,我觉得还是 GCC 的选择比较好,list 的优势应该保留,但能在 size() 函数处给个 warning 什么的就好了。
我想还有一个选择是这样:在 list 内部用一个 bool 变量指示当前内部 size 值是有效还是无效。在通常操作时 bool 保持 true,这样在 size() 时直接返回原值即可;在 splice() 后将此 bool 值置为 false 并不计算长度,直到最后又有需要 size() 时发现 bool 是 false 则从头再来一遍 distance() 并再将 bool 置为 true。暂时只想出这么一个算是折中的方法,基本上都能保持两边 O(1) 的效率,但相应其他各关于元素数量的函数内部都要多一个判断当前 size 值是有效还是无效并选择是否改变其值。反正总是不能非常完美
嘛...本来只是发现 size() 的效率问题,没想到却扯出这么一桩事出来...也算长知识了吧